kaiyun官方网app下载app 大模型训练技术:使用QLM提升Qwen2-7B 128k训练效率3.4倍
一、引言
自 Transformer 架构问世以来,大模型领域进展迅速,短短几年间模型参数规模攀升至天文数字,轻松跨过万亿大关。面对如此庞然大物,传统的单机单 GPU 训练方式显然力不从心。因此,单机多 GPU、多机多 GPU 的分布式训练方案应运而生,成为驾驭超大规模模型的必要手段。然而,这一转变并非一帆风顺,各种挑战随之而来,如:显存要求高、训练周期长、模型吞吐要求高。
为了攻克这些难点,一系列以提高效率为目标的并行计算策略和内存优化技术被引入到分布式训练过程中,编织了一张广阔的技术网络。智能工程部结合集群算力调度,充分考虑任务特点和硬件环境,融入并行优化技术,精心调整参数配置,最终实现训练效率和资源利用率的双重飞跃。
本文将简单介绍这些技术在分布式训练中的作用,并用实际案例展示如何利用这些技术提高大模型训练和微调的效率。
2. 相关技术原理
2.1 并行技术
随着大模型训练性能的要求,各种并行技术被应用于分布式训练,主要有:
1、数据并行(DP):将训练数据分成多个batch,每个batch分配给不同的设备进行训练,每个设备都有完整的模型,在本地计算loss和梯度,然后通过同步所有设备的梯度来更新模型参数。
2、流水线并行(PP):将模型按层划分为多个阶段,每个阶段由不同的设备处理。当每个设备处理完一个微批次时,可以并行处理其他微批次,从而提高设备利用率,减少等待时间。
3. 张量并行(TP):将模型中的张量分成更小的块,分配给不同的计算节点,每个节点只计算部分张量,节点之间需要进行通信将结果合并。
4.序列并行(SP):主要用于训练长序列数据,将长序列拆分成多个子序列并同时在不同的设备上处理这些子序列。
5、上下文并行(CP):可以看作是SP的加强版,它将输入输出激活全部在序列维度上拆分,分别在不同的设备上进行计算,可以有效提升长上下文相关任务的训练效率。
下面将详细介绍各种并行技术的原理和特点。
2.1.1 数据并行
图2.1 数据并行图
数据并行在每个 worker 上复制一个模型,并将数据集划分到多个 worker 上;每个 worker 接收不同的批次数据并执行前向传播,在反向,worker 定期汇总其梯度,以确保所有 worker 看到的权重版本一致。这种方法可以有效提高模型的训练速度。
2.1.2 模型并行
根据拆分方式不同,模型并行分为流水线并行和张量并行。
2.1.2.1 流水线并行
流水线并行就是将模型逐层切分[1],将模型的不同层划分为不同的stage,放在不同的worker上。如图2.2所示,前几层放在一个worker上,后几层放在另一个worker上。每部分计算完成后,数据再传递到下一个stage,直至整个模型计算完成。

图2.2 层分割示意图
但这种划分方式会在训练过程中产生大量的时间泡沫,如图2.3所示,由于在前一个worker还未训练完成时,下一个worker就一直在等待,极大的浪费了GPU的资源。
图2.3 简单流水线图
对于这种 F-then-B(Forward then Backward)方案,Megatron-LM 采用的是 1F1B(One Forward pass following one Backward pass)策略 [2]。如图 2.4 所示,一批训练数据被分成多个微批次,每一批数据训练完成后,立即传递给下一个 worker,当前 worker 立即开始训练下一个微批次。这样,bubble 时间就缩短了,GPU 利用率也提高了。如果采用交错调度,bubble 时间还可以进一步缩短。
图2.4 1F1B管线示意图
2.1.2.2 张量并行
张量并行是模型的层内切分,如图2.5所示,主要用于加速矩阵运算。将输入矩阵和参数矩阵合理分块计算,按照矩阵切分方式可分为行并行和列并行。
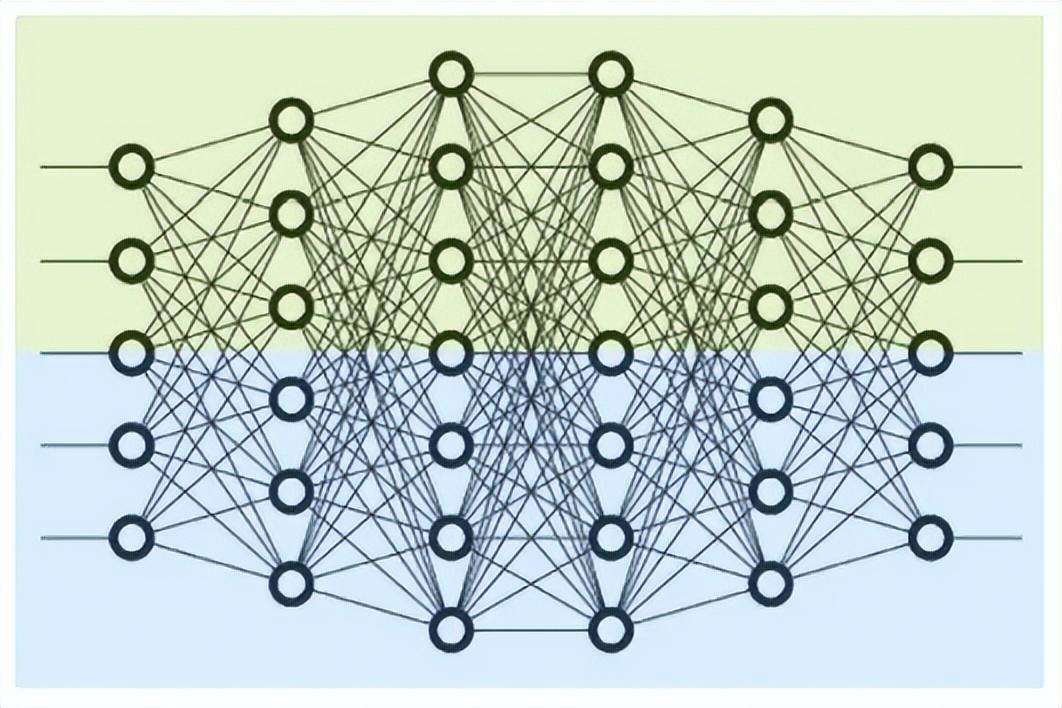
图2.5 层内分割示意图
1. 行并行
如图2.6所示,若A按行分为A1和A2,则需要按列分为X1和X2,即:
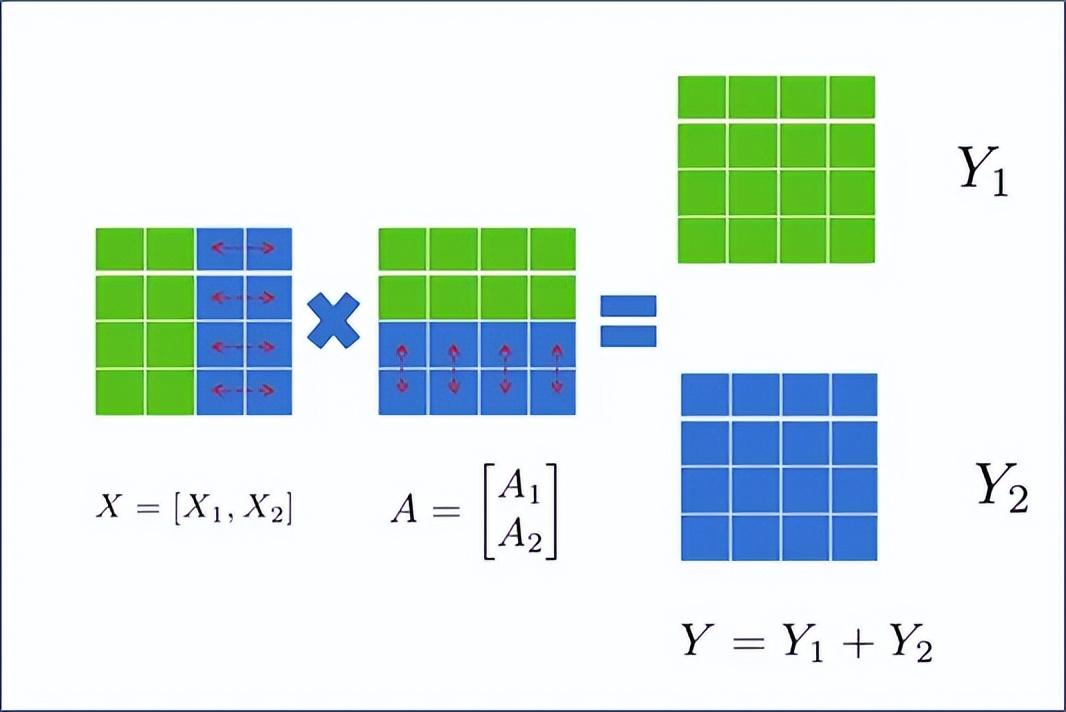
图2.6 矩阵按行拆分操作示意图
这样就将矩阵分成了块,放在两张卡上计算,计算完成后再通过All-Reduce获取其他卡上的计算结果,得到最终的Y。
从正向和反向的角度看行并行过程,f算子在正向过程中会把X拆分成X1和X2,分别放在不同的GPU上,在反向过程中会通过All-Gather把返回的梯度拼接起来,f算子在正向过程中会通过All-Reduce把结果累加起来,在反向过程中则分别计算梯度。
图2.7 并行化前逆向过程示意图
2. 列平行度
如图2.8所示,若将A按列拆分为A1和A2,则X不需要拆分,即:
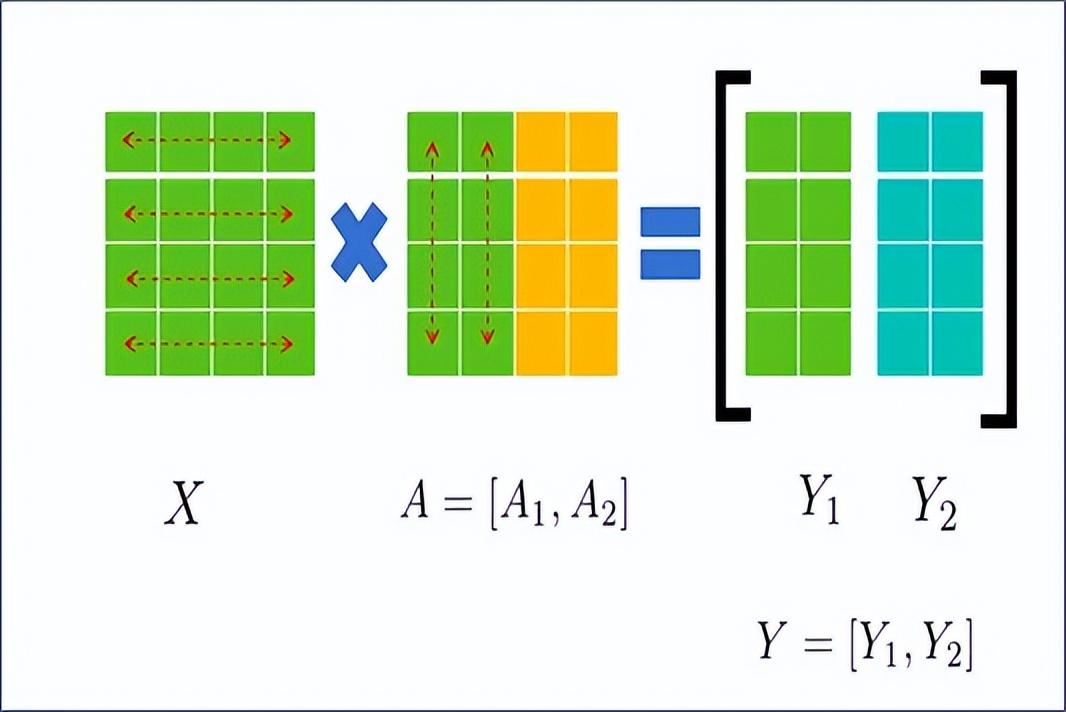
图2.8 矩阵列拆分操作示意图
从正向和反向的角度看,列并行过程就是,在正向过程中,f算子会把X分散到两张卡上,在反向过程中,通过All-Reduce把返回的梯度累加起来;在正向过程中,f算子会通过All-Gather把结果连接起来,在反向过程中,会把梯度矩阵拆分成两部分然后返回。
图2.9 柱并行化前逆过程示意图
3. Transformer 中的张量并行
Transformer结构由Attention模块和MLP模块组成,如图2.10所示,Attention模块由SelfAttention层+Dropout层组成;MLP模块有两个GEMM,第一个GEMM将维度从H改成4H,第二个GEMM将维度从4H改回H,中间使用了GeLU激活函数;各层的连接上也使用了残差连接。
图2.10 Transformer结构图
对于 Attention 模块,可以利用多头 Attention 操作固有的并行性,拆分自注意力模块,对查询(Query,Q)、键(Key,K)、值(Value,V)矩阵进行列并行优化,同时输出线性层可以直接对 Attention 层的输出进行操作。
图 2.11 自注意力机制
对于 MLP 模块中的第一个 GEMM,相应的操作可以表示为 Y = GeLU (XA)。如果将 A 拆分为行,则
但由于 GeLU 是一个非线性函数,
因此,如果使用行并行,则必须在 GeLU 操作之前添加 All-Reduce 同步点,以允许不同 GPU 之间交换信息。另一种并行方法是列并行。如果使用列并行,则可以将 GeLU 函数独立应用于每个 GEMM 的输出,对应于
这种方法不需要同步点。因此,第一个 GEMM 沿列并行划分,第二个 GEMM 沿行划分。GeLU 的输出可以直接用作下一个 GeLU 的输入,无需任何通信。最终的整体并行方法如图 2.12 所示:
图 2.12 MLP
2.1.3 顺序并行
序列并行采用均分序列维度的策略来降低模型内存占用。Megatron-LM 在张量并行的基础上,将 Transformer 层中的 LayerNorm 和 Dropout 操作的输入按照序列长度维度进行拆分[3],使得每个设备只需要处理一部分序列的 Dropout 和 LayerNorm 操作。
当然,额外的划分会导致通信模式的变化。在Transformer层,TP的通信模式包括两个正向All-Reduce和两个反向All-Reduce。但是由于SP划分了序列维度,传统的All-Reduce已经不再适用。为了将SP生成的结果在各个设备上聚集,满足SP与TP之间的数据传输需求,需要引入All-Gather;而为了将TP生成的结果传递到序列并行层,需要引入Reduce-Scatter。因此如图2.13所示,引入了两个算子和,分别代表正向All-Gather和反向Reduce-Scatterkaiyun体育登录网页入口,和代表正向Reduce-Scatter和反向All-Gather。由于一个All-Reduce相当于一个Reduce-Scatter和一个All-Gather,因此在开启TP时开启SP并不会增加额外的通信。 相反,在反向实现中,Reduce-Scatter和权重梯度的计算是重叠的,进一步减少了通信占用的时间。
图 2.13 启用 TP 和 SP 的 Transformer 层
2.1.4 语境平行
上下文并行也是一种序列维度上的并行化方案[4],它对长文本处理任务有很好的优化。与 SP 不同的是,SP 只在序列维度上拆分了 LayerNorm 和 Dropout 输出的激活值,而 CP 则在序列维度上拆分了所有输入的输入和所有输出的激活值。CP 可以看作是 SP 的增强版。
为了减少激活内存的使用,每个 GPU 在前向传递中只存储一个序列块的 KV,在后向传递中再次收集 KV。KV 通信发生在一个 GPU 和其他 TP 组对应 GPU 之间。在底层,这些 All-Gather 和 Reduce-Scatter 操作转换为环形拓扑中的点对点通信。此外,还可以通过使用多查询注意或分组查询注意来交换 KV 以减少通信。
以图2.14中的TP2-CP2 Transformer网络为例,Attention前面的算子为CP的通信算子,其他的为TP的通信算子。AG代表All-Gather,RS代表Reduce-Scatter,AG/RS代表Forward All-Gather Reverse Reduce-Scatter,RS/AG代表Forward Reduce-Scatter Reverse All-Gather。
图 2.14 启用 TP 和 CP 的 Transformer 层
2.2 显存优化
2.2.1 训练过程中的显存分析
在大模型的训练过程中,GPU的瓶颈往往不是它的算力,而是显存的容量限制,占用显存的部分主要有模型权重、梯度、优化器、激活值等。
1. 模型重量
在模型训练时,一般有fp32、fp16、bf16、int8几种模型保存格式。fp32使用32位保存一个模型参数,int8使用8位,fp16和bf16使用16位保存。假设模型参数个数为Ψ,训练时模型以bf16精度保存,其权重本身占用的显存约为2Ψ(Bytes)(如无特殊说明,显存单位也是Bytes)。
2.渐变
梯度数据类型通常和模型数据类型匹配,在混合精度训练中,梯度类型一般为fp16,对于fp32训练,梯度占用显存4Ψ,对于fp16/混合精度训练,梯度占用显存2Ψ。
3. 优化器
目前大模型训练普遍使用Adam优化器,训练时需要用到动量和二阶动量,如果优化器使用fp32格式保存参数,其占用的显存为12Ψ。
4. 激活值
在大型模型训练中,Embedding 层和最后的 LayerNorm 和输出层占用的内存与 Transformer 块产生的内存相比可以忽略不计。
假设激活值的数据类型为fp16,输入长度为s,batch size为b,hidden的维度为h,attention head的数量为a,模型层数为L,则:
各层Transformer block产生的激活值的内存占用为:
如图2.15所示,开启TP后,Transformer层部分模块的显存可以在不同设备间共享,不能共享的显存主要由两个LayerNorm block和两个Dropout block产生,共计2个。
图 2.15 启用 TP 的 Transformer 层
假设张量并行度为t,Transformer每层显存占用为:
如果再次开启SP,Transformer层中的LayerNorm和Dropout块也会进行分裂,在序列维度上对张量进行分裂,分裂次数等于张量并行度的大小。那么每层激活值的内存占用为:
若采用流水线并行,由于第一阶段需要存储p个微批次的激活值,因此无论并行规模p为多少,存储第一阶段激活值所需的显存为:
如果使用交叉调度,则总活动视频内存将根据 (1+(p-1)/pm) 进行缩放,其中 m 是交叉管道的大小。
2.2.2 显存优化技术
显存优化技术主要通过减少数据冗余、用计算代替存储、压缩数据表示等方式来降低上述部分的显存占用率。下面介绍两种常用的节省显存的方法。
1. 重新计算
激活重新计算技术,它仅存储每层的输入激活值,并在需要时重新计算其他激活值。
如果选择根据TP重新计算,则显存使用量为
如果再次打开 SP,视频内存将
如果重新计算全部量,则视频内存
虽然全量重新计算可以大幅降低激活值的内存占用,但是会导致30%-40%的计算性能损失,训练时需要根据实际情况决定采用哪种重新计算方式。
2. ZeRO
ZeRO[5] 是零冗余优化器的缩写,是 DeepSpeed 项目为解决数据并行训练中常见的内存冗余问题而提出的一种创新方法。在传统的数据并行训练中,模型参数、梯度和优化器状态在每个 GPU 上都是完全复制的,从而导致内存冗余。
ZeRO 技术通过将这些数据分布并共享到不同的 GPU 上,从而降低了每个 GPU 的内存需求。具体来说,ZeRO 提出了三种策略,分别对应分别存储优化器参数、分别存储优化器和梯度以及分别存储三个参数。具体效果可见图 2.16:
图 2.16 ZeRO 的三个层级
假设模型参数Ψ=7.5B,GPU数量Nd=64,优化器状态的显存乘数为K,对于Adam来说为K=12。对于Baseline(DP),每个GPU都要保存所有的参数、梯度和优化器状态,假设使用fp16保存模型,则总显存为(2+2+K)Ψ,也就是120GB。对于,将KΨ显存分成Nd个GPU,因此每个GPU上的显存为2Ψ+2Ψ+KΨ/Nd,也就是31.4GB。对于,将KΨ+2Ψ优化器状态和梯度分成Nd个GPU,每个GPU为2Ψ+(2+k)Ψ/Nd,也就是16.6GB。最后将全部除以2,因此每个GPU为(2+2+K)Ψ/Nd,也就是1.9GB。
与更高级别的 ZeRO 相比,保留了模型参数的完整复制,避免了计算过程中频繁的数据交换,保持了较高的计算效率;与和相比,仅涉及优化器状态的并行化,而不涉及模型权重和梯度的分裂,实现相对简单,这使得它在许多情况下成为实用的选择。
3. QLM 加速实践经验
QLM,全称奇虎语言模型,是智能工程部基于目前主流大模型加速框架 Megatron-LM 开发的一体化框架,支持 Huggingface、Megatron 多种模型格式的转换、预训练、评估、微调、分析等,结合 TAI 平台可有效支持 Qwen、zhinao 等千卡训练、长文本微调等各类任务。
图3.1 QLM框架及功能图
下面演示如何使用QLM框架支撑业务部门128k长文本微调提速实践,通过以上优化提速技术,长文本微调速率从120s/sample提升到35.5s/sample,提升3.4倍。
基础版本在四台H800机器上训练,由于资源有限,优化在四台A100上进行云开·全站apply体育官方平台,H800与A100的性能如下图所示:
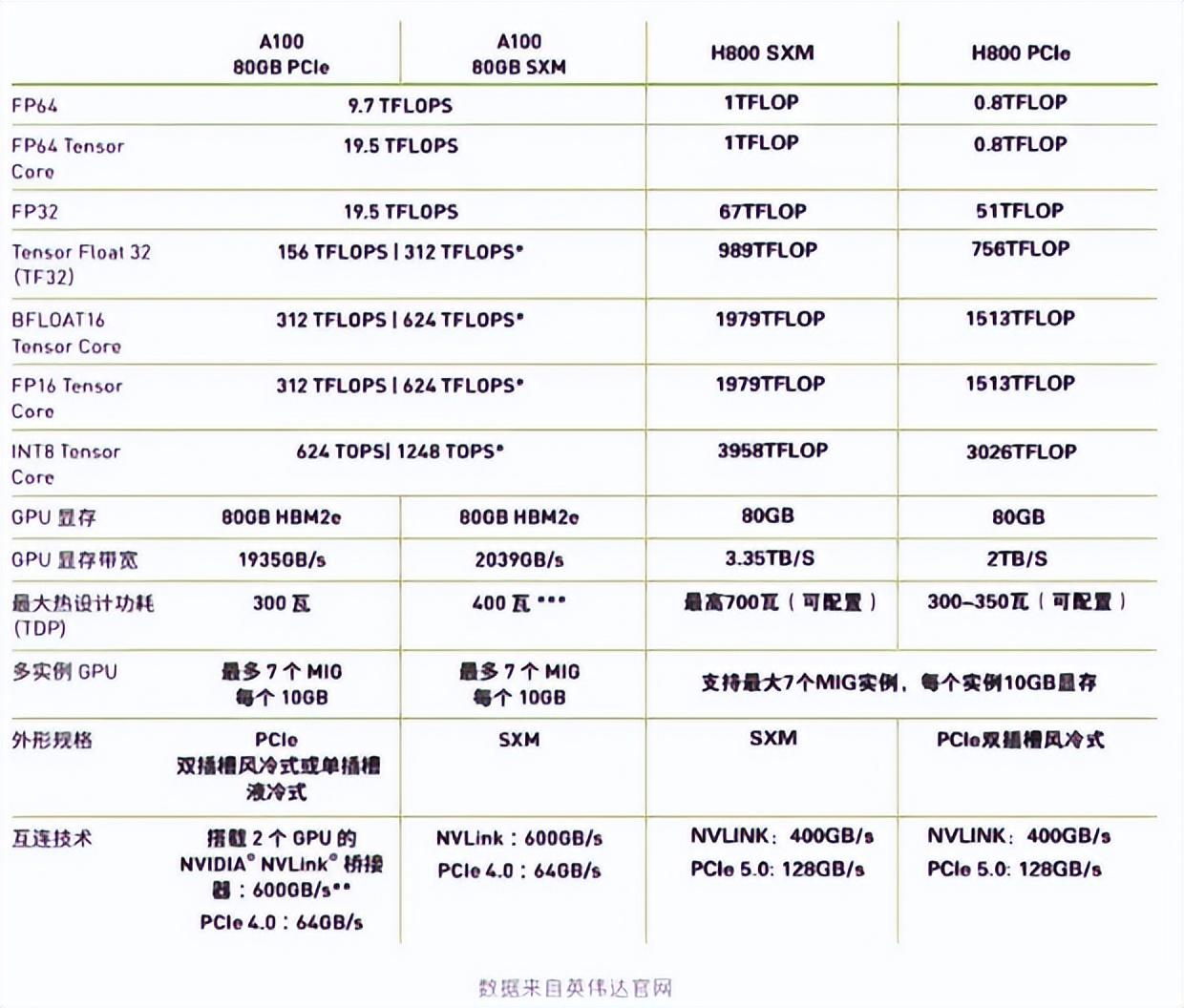
图3.2 不同GPU性能参数对比
并行提速调优过程中,可以先尝试开启DP,对输入数据进行切片,提高数据处理速率。基础版本以DP1-TP4-PP1-SP-CP8的配置实现,基础版本不开启DP,由于需要GPU总数等于DP*TP*PP*CP,所以需要相应减少CP数量。开启DP的同时,使用--overlap-grad-reduce --overlap-param-gather两个参数进行DP通信时的重叠,可以提升12%的性能。如果要开启MP,则优先开启TP,因为TP是机器节点内部通信,可以通过NVLINK加速,相比PP通信效率更高。另外由于模型特性,TP最大值固定为4,因此无需调整。
由于任务上下文较长,开启SP和CP是较好的选择,但CP值也不是越大越好,最佳值需要经过仔细测试和综合考虑后才能确定,最终调优结果如表3.1所示:
表 3.1 不同优化参数下的结果

v2 版本在优化过程中遭遇了 OOM,这促使我们在 v3 版本中采取了激进的显存碎片清理策略,力争在每个计算周期结束后释放不再需要的显存空间。虽然这一举措对训练速度有一定影响,但相较于 v1 版本的速度和 v2 版本的 OOM 问题kaiyun官方网app下载app,v3 版本最终以 35.5s/sample 的速度实现了稳定运行,成功平衡了性能与资源利用率的关系。
值得注意的是,v3 及之前版本均采用了全量重新计算的方式,这将带来约 30% 的性能损失。鉴于此,v4 版本为了提升效率尝试降低重新计算的层级,但遗憾的是,此次调整再次触发了 OOM 异常。此时尚未开启 PP 策略。v5 开启 PP 策略,虽然在速度上超越了基础版本,但与 V3 版本的峰值性能相比仍有不小差距。因此如图 3.2 所示,本次调优达到的最优效率为 35.5s/sample,相比基础版本提升了 3.4 倍,模型推理结果达到了预期效果。

图3.2 调优前后速率对比示意图
四、结论
本文讲解了大型模型分布式训练过程中并行优化技术的基本原理,分析了模型训练过程中的显存占用情况,以及如何更好的节省显存,并结合实际应用场景展示了 QLM 如何利用这些技术来提升长文本任务的训练效率。
随着大模型的快速演进,未来的训练场景必然会遭遇“三重壁垒”——内存墙、通信墙、计算墙,这三大瓶颈将带来严峻的挑战。面对这种情况,如何精简显存使用量,降低跨节点通信成本,提升计算性能和效率,成为了QLM团队不懈的追求,我们正在全力以赴探索创新解决方案,构建更高效、可持续的大模型生态。
参考:
[1] MegatronLM序列模型并行训练(Sequence Parallel)详解,
[2]Narayanan D, Shoeybi M, Casper J 等人。使用 megatron-lm 在 GPU 集群上进行高效的大规模语言模型训练[C]//国际高性能计算、网络、存储和分析会议论文集。2021:1-15。
[3]Korthikanti VA, Casper J, Lym S 等人。减少大型 Transformer 模型中的激活重新计算[J]。机器学习与系统学报,2023 年,5:341-353。
[4]上下文并行概述,#context-parallelism-overview
[5] Rajbhandari S, Rasley J, Ruwase O 等人。零:面向训练万亿参数模型的内存优化[C]//SC20:国际高性能计算、网络、存储和分析会议。IEEE,2020:1-16。
 鲁ICP备18019460号-4
鲁ICP备18019460号-4
我要评论