pg棋牌 图深度学习入门教程(六)——注意力机制与图注意力

概括:
我还没学完深度学习。为什么深度学习又来了?别害怕,这里有系统教程,可以带你零基础知识直接上图深度学习。它还将定期更新。
本教程是免费教程系列,我们力争每月更新2到4篇文章。
主要是基于图深度学习的入门内容。描述了最基本的基础知识,包括深度学习、数学、图神经网络等相关内容。本教程摘录自 Code Doctor Studio 出版的所有书籍。强调完整的知识体系和学习指南。实践方面,不会涉及太多基础内容(实践和体验内容请参考原书)。
文章中使用的框架主要是PyTorch和TensorFlow。默认情况下,读者已经掌握了Python和TensorFlow的基础知识。如果涉及到PyTorch,会顺便介绍一下相关的入门使用。
本教程主要针对:
本文主要介绍注意力机制模型以及注意力机制在图神经网络领域的应用——图注意力模型(GAT)。
1 神经网络中的注意力机制
神经网络的注意力机制与人类处理事物时的“注意力”含义相同,即关注一堆信息中的一部分信息,并对这部分信息进行处理和分析。
在生活中,注意力的应用随处可见:当我们看某物时,我们通常会关注眼前图像中的某个地方;在阅读一篇文章时,我们常常会关注文章的部分文字。听音乐时,你也会根据音乐中不同的旋律产生不同强度的情绪,甚至会记住某些旋律片段。
在神经网络中,利用注意力机制可以达到更好的拟合效果。注意力机制使得神经网络能够忽略不重要的特征向量,专注于计算有用的特征向量。在丢弃干扰拟合结果的无用特征的同时,也提高了计算速度。
1.1 注意力机制技术的兴起
注意力机制并不是一个非常新的技术,但只是近年来才受到广泛关注。将其推上顶峰的事件主要是一篇论文《Attention is All You Need》(arXiv: 1706.03762,其中附有 Transformer 模型)。 2017)
Transformer模型是NLP中的经典模型。它放弃了传统的RNN结构,而是使用注意力方法来处理序列任务。
循环神经网络的最大缺陷是其序列依赖性。上一时刻的隐状态输出(以及LSTM的记忆单元)和此时的输入一起作为新一轮的晶胞处理材料,以此类推。由于自回归的特性,仅仅依靠一两个矩阵来完整、无偏地记录过去几十甚至上百个时间步的序列信息显然是不可能的。在训练过程中反复调整权重pg麻将胡了试玩平台,这可能是不可能的。它只需应用于测试集的要求即可。更不用说训练过程中梯度消失带来的优化难度。这些缺陷从LSTM的单元公式中可以清楚地看出。后续新模型的创建者从未推出能够在保证特征提取能力的同时完美解决上述问题的解决方案,直到 Transformer 出现。
利用带有Attention机制的循环神经网络进行各种变形形成Encoder,然后连接一个Decoder作为输出层pg电子赏金试玩app,形成Encoder-Decoder架构,是前夕各种主流NLP神经网络的设计思路变压器的诞生。
例如,动态协同注意力网络(DCN)使用单向LSTM+协作注意力编码器作为Encoder,对文本和问题中的隐藏状态进行多次线性/非线性变换、合并和乘法,以获得联合矩阵,然后将其放入由单向LSTM、双向LSTM和Highway Maxout Networks(HMN)组成的Dynamic Pointing Decoder中得出预测结果;双向注意力网络流(BiDAF)除了由循环神经网络组成的特殊结构之外,还使用问题到文本和文本到问题的注意力矩阵来提取特征。在问答领域,还包括DrQA、AoA、r-Net、改造后性能提升的各种模型,以及其他领域的更多。但无论怎样,你永远摆脱不了RNN或CNN的阴影。 Transformer 是第一个使用 self-attention 机制来完全摆脱对循环或卷积神经网络的依赖的模型。其结构如下
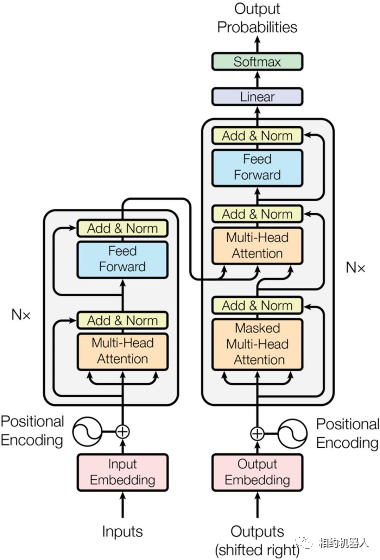
1.2 什么是注意力机制?
神经网络中的注意力机制主要是通过注意力分数来实现的。注意力分数是一个从0到1的值,受注意力机制影响的所有分数的总和为1。每个注意力分数代表分配给当前项目的注意力权重。
注意力分数往往是在模型训练时从神经网络的权重参数中学习到的,最终使用 SoftMax 进行计算。该机制可以在任何神经网络模型中发挥作用。例如:
(1)注意力机制可以作用于RNN模型中的每个序列,使得RNN模型对序列中的各个样本给予不同的关注。

该方法常用于RNN模型中RNN层输出结果之后。
暗示:
注意机制也可以用在 RNN 模型中的 Seq2Seq 框架中。
(2)注意力机制还可以作用于模型输出的特征向量。
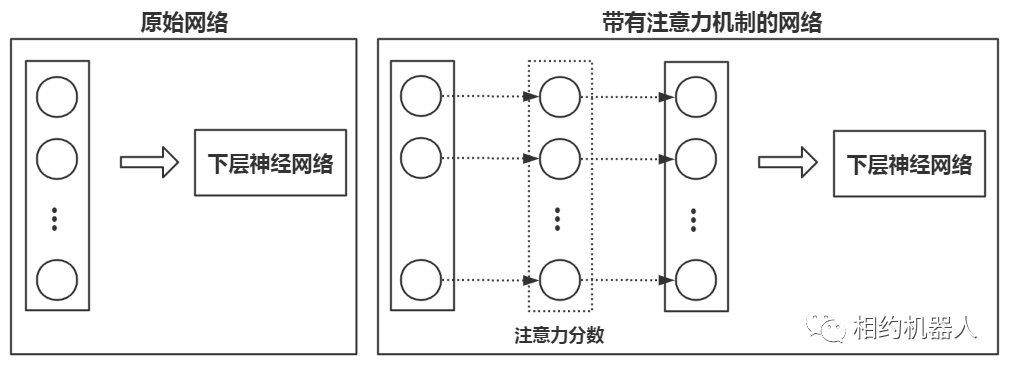
这种对特征向量进行注意力计算的方法有着更广泛的应用。它不仅可以应用于循环神经网络,还可以应用于卷积神经网络甚至图神经网络。
1.3 注意力机制的软、硬模式
实际应用中,注意力计算模式有两种:软模式和硬模式。
Soft Attention:所有数据都会被关注,计算相应的注意力权重,不设置过滤条件。
Hard Attention:生成注意力权重后,会筛选掉一部分不满足条件的注意力,使其注意力权重为0,可以理解为不再关注不满足条件的部分状况。
1.4 注意力机制模型原理
注意力机制模型是指完全利用注意力机制构建的模型。除了辅助其他神经网络之外,注意力机制本身也具有拟合能力。
1.注意力机制模型原理
注意力机制模型的原理描述起来非常简单:将具体任务视为三个角色:query、key、value(分别缩写为q、k、v)。其中,q是要查询的任务,k和v是一对一的键值对。目的是利用q求出k中对应的v值。
在具体实现上,会比基本原理稍微复杂一些,见下面的公式。

2.注意力机制模型的应用
注意力机制模型非常适合序列到序列(Seq2Seq)拟合任务。例如:在阅读理解任务中,文章可以看作是Q,阅读理解问题和答案可以看作是K和V组成的键值对。下面以翻译任务为例介绍一下详细装修流程:

1.5.多头注意力机制
多头注意力机制技术是对原有注意力机制模型的改进。也是Transformer模型的主要技术。该技术可以表示为:Y=MultiHead(Q,K,V)。原理如图所示。
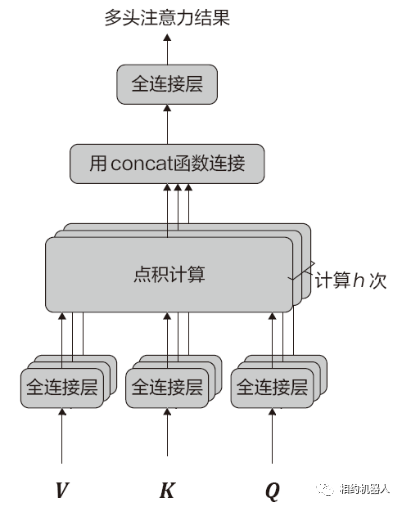
多头注意力机制的工作原理如下:
(1) 使用参数矩阵将Q、K、V映射到全连接层。
(2) 对步骤(1)中变换后的三个结果进行点积运算。
(3)重复步骤(1)和(2)h次,每执行一次步骤(1),就使用一个新的参数矩阵(参数不共享)。
(4)使用concat函数连接计算h次后的最终结果。
其中,步骤(4)的操作与多分支卷积(将在下卷中详细介绍)技术非常相似,其理论可以解释为:
(1)每一次注意力机制操作都会引起原始数据中某一方面特征的注意力变换(获得局部注意力特征)。
(2)多次注意力机制操作发生后,将获得更多方向的局部注意力特征。
(3)结合所有局部注意力特征,通过神经网络将其转化为整体特征,达到拟合效果。
1.6.自注意力机制
自注意力机制也称为内部注意力机制,用于发现序列数据的内部特征。具体方法是将Q、K、V改成X。即Attention(X,X,X)。
使用多头注意力机制训练的自注意力特征可以用于各种任务,例如Seq2Seq模型(输入和输出都是序列数据的模型,将在下卷中详细介绍)、分类模型,并且可以达到很好的效果,即Y=MultiHead(X,X,X)。
1.7 什么是位置向量词嵌入
由于注意力机制的本质是键值搜索机制,它无法反映查询时Q的内部关系特征。因此,谷歌在实现注意力机制的模型中加入了位置向量技术。
带位置向量的词嵌入是指在现有的词嵌入技术中添加位置信息。实施时,具体步骤如下:
(1)使用sin(正弦)和cos(余弦)算法计算词嵌入中的每个元素。
(2)使用concat函数将步骤(1)中sin和cos计算的结果连接起来,作为最终的位置信息。
位置信息的转换公式比较复杂,这里不再展开。详细请看下面的代码:
代码语言:javascript
复制
def Position_Embedding(inputs, position_size):
batch_size,seq_len = tf.shape(inputs)[0],tf.shape(inputs)[1]
position_j = 1. / tf.pow(10000., \
2 * tf.range(position_size / 2, dtype=tf.float32 \
) / position_size)
position_j = tf.expand_dims(position_j, 0)
position_i = tf.range(tf.cast(seq_len, tf.float32), dtype=tf.float32)
position_i = tf.expand_dims(position_i, 1)
position_ij = tf.matmul(position_i, position_j)
position_ij = tf.concat([tf.cos(position_ij), tf.sin(position_ij)], 1)
position_embedding = tf.expand_dims(position_ij, 0) \
+ tf.zeros((batch_size, seq_len, position_size))
return position_embedding在示例代码中,函数Position_Embedding的输入和输出为:
通过函数Position_Embedding的输入和输出,可以清楚地看到词嵌入中添加了位置向量信息。转换后的结果可以像普通的词嵌入一样在模型中使用。
2. Attention机制和Seq2Seq框架
具有注意力机制的Seq2Seq(attention_Seq2Seq)框架通常用于解决Seq2Seq任务。为了避免读者混淆概念,下面对Seq2Seq相关的任务、框架、接口、模型进行统一解释。
2.1.了解Seq2Seq框架
Seq2Seq任务的主流解决方案是使用Seq2Seq框架(即Encoder-Decoder框架)。
Encoder-Decoder框架的工作机制如下。
(1) 使用Encoder将输入编码映射到语义空间,得到固定维度的向量。该向量表示输入的语义。
(2) 使用解码器对语义向量进行解码,得到所需的输出。如果输出是文本,则解码器通常是语言模型。
Encoder-Decoder框架的结构如图所示。
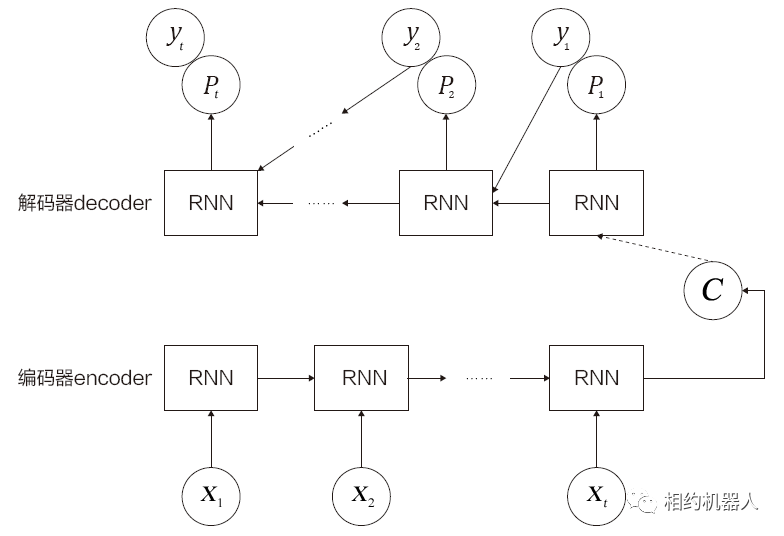
该网络框架擅长解决:语音到文本、文本到文本、图像到文本、文本到图像等转换任务。
2.2.了解带有注意力机制的Seq2Seq框架
注意力机制可以用来计算输入和输出之间的相似度。一般应用于Seq2Seq框架中的编码器(Encoder)和解码器(Decoder)之间,通过对输入到编码器的每个词赋予不同的注意力权重来影响最终的生成结果。这种网络可以处理更长的序列任务。其具体结构如图所示。
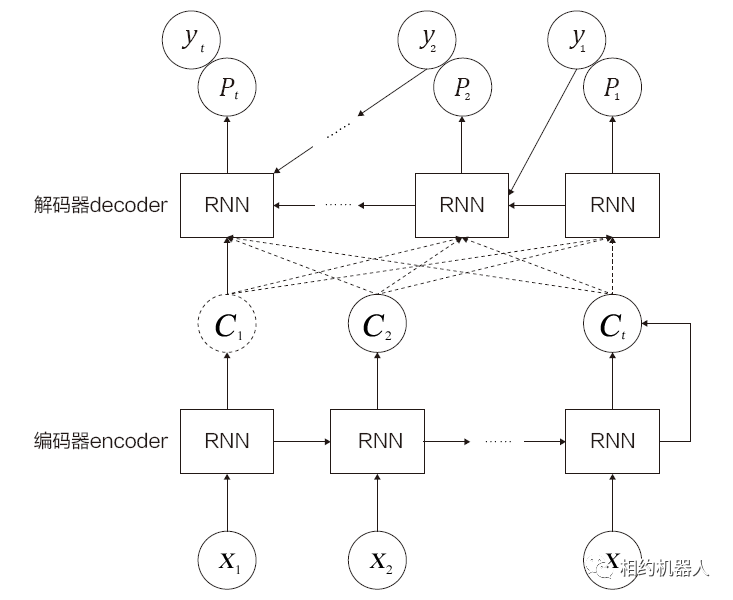
图中的框架只是注意力机制之一。在实际应用中pg电子麻将胡了,注意力机制还有许多其他变体。其中包括LuongAttention、BahdanauAttention、LocationSensitiveAttention等。有关注意力机制的更多信息,还可以参考论文:
2.3.理解 BahdanauAttention 和 LuongAttention
在TensorFlow的Seq2Seq接口中,实现了两个注意力机制类接口:BahdanauAttention和LuongAttention。在介绍这两种注意力机制的区别之前,我们首先系统地介绍一下注意力机制的几种实现方法。
1.注意力机制实现总结
注意力机制的实现大致可以分为四种方法:
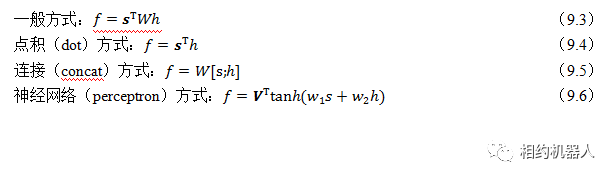
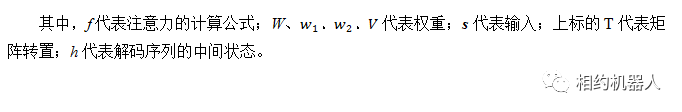
2.4. BahdanauAttention 和 LuongAttention 的区别
两种注意力机制 BahdanauAttention 和 LuongAttention 分别由 Bahdanau 和 Luong 两位作者实现。前者采用通用方法实现,见式(9.3);后者是使用神经网络方法实现的,见方程(9.6)。相应论文如下:
2.5. normed_BahdanauAttention 和scaled_LuongAttention
BahdanauAttention类中有一个权重归一化版本(normed_BahdanauAttention),可以加快随机梯度下降的收敛速度。使用时只需将初始化函数中的参数normalize设置为True即可。
详细信息请参考以下论文:
相应的权重归一化版本(scaled_LuongAttention)也在 LuongAttention 类中实现。使用时只需将初始化函数中的参数scale设置为True即可。
2.6 理解单调注意力机制
单调注意机制在原有注意机制的基础上增加了单调约束。这个单调约束的内容是:
(1) 假设在生成输出序列的过程中,模型从左到右处理输入序列。
(2)当某个输入序列对应的输出被聚焦时,出现在该输入序列之前的其他输入在后续输出中将不会被聚焦。
即已经关注的输入序列在之前的序列中将不再被关注。
 鲁ICP备18019460号-4
鲁ICP备18019460号-4
我要评论