pg赏金女王单机版试玩平台 前沿重器[27] | 从遗忘问题到预训练轻量化微调
边疆武器
专栏主要分享各大厂商、顶级会议的论文和分享,并从中提取关键精华分享给大家,与大家一起掌握前沿技术。详细介绍:.
最近,我再次总结了我的历史文章,总计50万字,100多篇文章。如果您有兴趣,可以看一下。如何获得:.
回顾过去的问题
所谓遗忘,在心理学上是指原本记得的某件事,但重播时却发现无法重播或重播有偏差的现象。所谓的“人工智能”也会出现与人类类似的问题。问题,那么这个问题在预训练模型中是如何出现的以及如何解决呢?本文将给出我的讨论。
背景
一旦模型完成训练,模型中的大部分参数都不会被触及。然而,随着预训练模型的出现,从“预训练”到“微调”的两阶段训练模型逐渐形成,问题也随之出现。 ,我们希望这个经过努力训练的预训练模型可以应用于很多领域,能够充分利用他的知识,事实上我们受益匪浅。然而值得注意的是,一旦我们继续训练,并且继续训练的内容与预训练任务有较大差异,参数更新后,我们很有可能会忘记一些我们学过的东西,我们甚至可能不会考虑验证它。这个问题并不存在,只是我们没有重视而已。
然而,很多人都注意到了这个问题。 2019年有一篇文章[1]比较好地论证了这种遗忘现象。虽然都是用在CV领域,但也足以引起我们的思考。 。
遗忘的机制
其实上面的背景我们已经讲了很多了。这里,我们来说说预训练模型的遗忘问题。
首先,我们都知道预训练模型是通过学习海量知识得到的。内部参数本质上代表了训练语料对应的语言信息和逻辑知识信息集。值得注意的是,存储了代表各种信息的参数。本质上,它是预训练模型中的参数。
那么,目前使用预训练模型的主要方式仍然是预训练+微调的模式,而微调注定会动摇训练好的预训练模型。这里移动的是预训练模型中的参数。如果变化的波动足够大,就很容易发生遗忘甚至灾难性遗忘。有时,你可以尝试用更高的学习率运行,你会发现学习几代后损失会突然发生变化。这其实很重要。现在是最简单的忘记方法。
不过,值得强调的是pg网赌软件下载,虽然参数在一定程度上代表了知识,但其层次太低了。参数的修改并不一定代表知识的丢失。知识可以由其他参数来表示。这也是为什么,在很多情况下,我们并没有看到微调带来很大的负面影响,而且大部分效果还是很好的。
要明白遗忘的核心本质是运动,或者是预训练模型中参数的过度变化,从而导致了这种遗忘。那么,有没有办法解决呢?答案是肯定的。
忘记解决方案
在NLP领域,说到遗忘,就会引用这篇文章[2](强烈建议仔细阅读这篇文章)。本文阐述了遗忘的本质,并总结了一些常见的解决方案,主要分为3点,从目前来看,本文的讨论还是可靠的。根据本文的描述,解决遗忘问题可以概括为三个思路:
如果把问题缩小到预训练模型的问题上,虽然重播方法很简单,但问题是预训练模型之前的任务难以重现且难以控制。毕竟数据和任务太重了,而正则化其实现在的方法有很多,而且用起来也很方便。从损失函数层面控制,修改不会很大。然而,从统计学的角度来看,这种训练实际上会让预测结果产生偏差。这种训练的最优解并不是新任务的最优解,而且会因为过于关注原始模型而拖累效果。
所以我其实想说预训练模型最好的方法其实是第三种方法,参数隔离,而且这方面其实已经有很多研究了。强烈推荐大家尝试一下,就是轻量级的Finetuning,对一个巨大的预训练模型进行微调,参数更新的成本非常高。如果能建一个比较小的模块,在微调阶段训练这个,成本会大大降低,而且不会很严重。虽然出发点本身就是为了解决遗忘问题,但训练的效率确实得到了很大的提升。
轻量级微调
轻量级微调,有4篇论文想简单说一下。
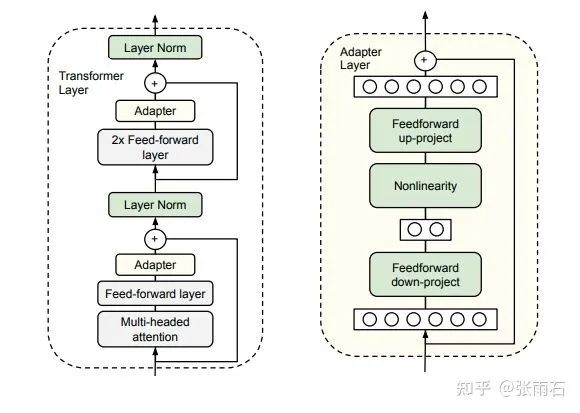
第一个是相对基本的适配器[3]。这个模型其实比较简单,用一张图就可以理解。它将两个全连接层添加到 Transformer 层。在训练阶段,只要训练这个全连接层就可以了,其他的attention部分就不用理解了。这种训练非常简单,训练参数数量也很少。
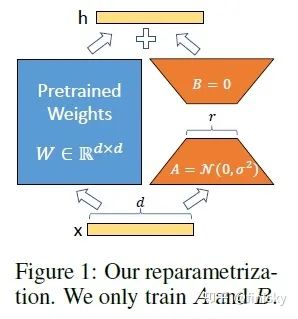
在第二篇文章中,我想谈谈LoRA[4]。与Adapter相比,其本质是将上下游串行关系变为并行关系。看图你就明白了。如下图所示,左边是预训练的模型pg麻将胡了试玩平台,右边是适配部分。从并行和串行来看,并行似乎有更多的可控空间。
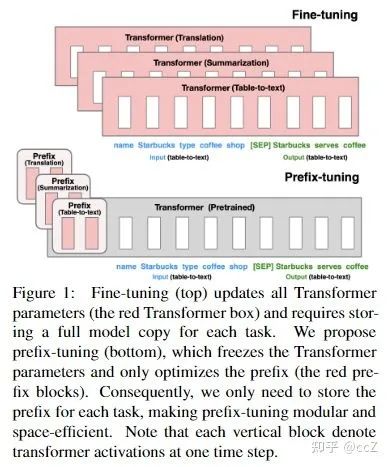
第三篇文章是前缀调优[5]。本文是基于LoRA的更激进的方法。这种做法其实和后面的提示还是挺接近的。大家也可以看下图,其实就是直接在预训练的模型前面添加一串predix。使用这种方法可以说非常熟悉预训练模型的底层理解。
第四篇可以说是前几部作品的集大成之作。它的长处在于可以结合上面提到的三篇论文,进行总结和整理。归结起来是这样的:
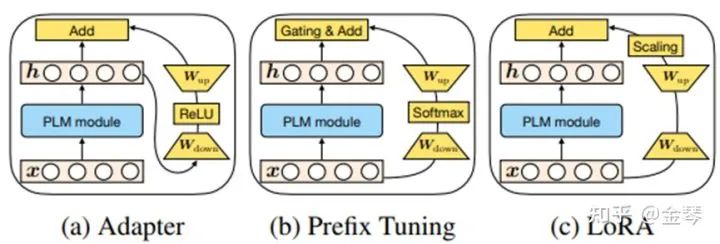
通过这样画图,大家可以看到上面三篇论文的特点,并尝试推导出新的更合理的优化方法。
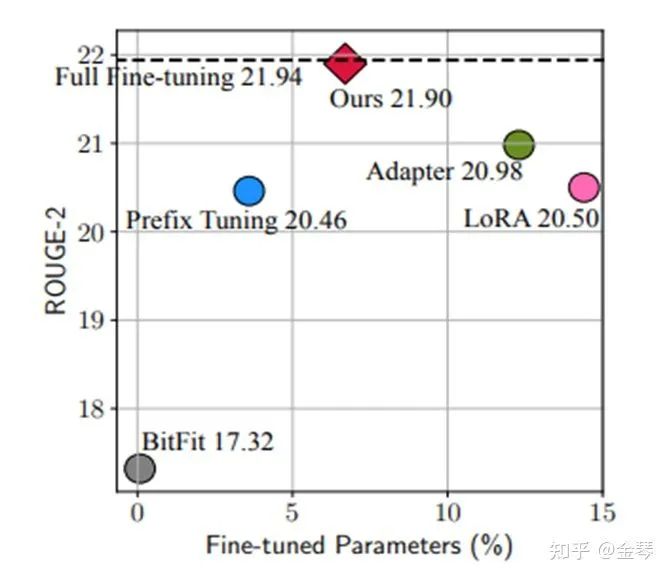
本质上我只是想讲的是轻量级微调的常用方法和核心研究工作。详细内容可以直接看论文。参考文献在文章最后。
轻量化微调探讨
轻量级微调本质上是在预训练的模型上添加一些插件。这些插件是可训练的,在更新参数的过程中,预训练的模型可以保持不动,经过实验,比传统的模型要好。微调对最终效果影响很小,可以说最大限度地提高了灵活性。每次有新任务来,就添加一个插件,直接训练。训练完成后,将会是一个新的模型。其实从某种程度上来说pg赏金女王单机版试玩平台,这是一种迁移学习的方法。文献[6]已经非常直白地阐述了这一点。它非常低。迁移成本和训练成本以及灾难性遗忘都可以在很大程度上得到解决。毕竟预训练模型的参数并没有改变,对吧?但是,如果预训练模型的参数保持不变,是否就意味着不存在遗忘呢?答案似乎是否定的。
预训练模型的参数保持不变并不意味着没有遗忘。根本原因是预训练模型预测的内容需要通过adapter进行改造,或者像LoRA一样进行拼接稀释。这种情况下,终究还是有损失的可能。的。然而,我们似乎很难判断是丢失还是损坏,因为最终,测试集说了算。至少我们已经尽了迄今为止已知的最大努力来“保留”预训练模型。
参考
[1]深度神经网络学习过程中实例遗忘的实证研究
[2] 持续学习调查:在分类任务中克服遗忘
[3] NLP 适配器的参数高效迁移学习
[4] LoRA:大型语言模型的低秩适应
[5] 前缀调优:优化生成连续提示
[6] 迈向参数高效迁移学习的统一观点

 鲁ICP备18019460号-4
鲁ICP备18019460号-4
我要评论