pg娱乐电子游戏 珍藏版 | 20道XGBoost面试题
大家一定都听说过XGBoost的名声。它不仅是数据科学竞赛的神器,而且在业界也得到了广泛的应用。本文与大家分享XGBoost多年收集的高频面试题。希望它能够加深您对XGBoost的理解,更重要的是,在寻找机会时提供一些帮助。
1. 简单介绍XGBoost
首先,我们需要谈谈GBDT。它是一种基于boosting增强策略的加性模型。训练时采用前向分布算法进行贪心学习。每次迭代都会学习 CART 树以适应先前的 t-1 树。预测结果与训练样本真实值之间的残差。
XGBoost对GBDT做了一系列优化,如损失函数的二阶泰勒展开、目标函数添加正则项、支持并行和默认缺失值处理等,极大地提高了可扩展性和训练速度,但其核心思想并没有发生明显的变化。
2.XGBoost和GBDT有什么区别? 3、XGBoost为什么采用泰勒二阶展开式? 4. XGBoost为什么可以并行训练? 5.为什么XGBoost很快? 6. XGBoost如何防止过拟合?
XGBoost在设计过程中,为了防止过拟合,做了很多优化,如下:
7. XGBoost 如何处理缺失值
XGBoost 模型的优点之一是它允许特征具有缺失值。缺失值处理如下:

find_split时缺失值处理的伪代码
8. XGBoost中如何计算叶子节点的权重
XGBoost目标函数的最终推导形式如下:

利用求二次函数最优值的知识,当目标函数达到最小值Obj*时,每个叶子节点的权重为wj*。
具体公式如下:
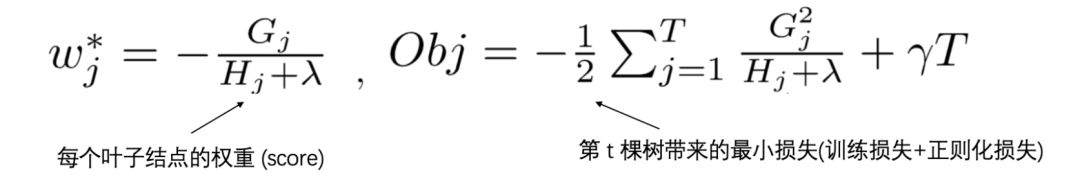
9. XGBoost 中树的停止生长条件 10. RF 和 GBDT 的区别
相似之处:
差异:
11. XGBoost 如何处理不平衡数据
对于不平衡的数据集,比如用户购买行为,肯定是极度不平衡的,这对XGBoost的训练影响很大。 XGBoost 有两种内置方法来解决该问题:
首先,如果你关心AUC,并用AUC来评估模型的性能,可以通过设置scale_pos_weight来平衡正负样本的权重。例如,当正负样本比例为1:10时,scale_pos_weight可以为10;
其次,如果你关心概率(预测分数的合理性),则无法重新平衡数据集(这会破坏数据的真实分布),并且应该将 max_delta_step 设置为有限的数字以帮助收敛(当基本型号为 LR)。
原话如下:
For common cases such as ads clickthrough log, the dataset is extremely imbalanced. This can affect the training of xgboost model,
and there are two ways to improve it.
If you care only about the ranking order (AUC) of your prediction
Balance the positive and negative weights, via scale_pos_weight
Use AUC for evaluation
If you care about predicting the right probability
In such a case, you cannot re-balance the dataset
In such a case, set parameter max_delta_step to a finite number (say 1) will help convergence
那么,源码中是如何使用scale_pos_weight来平衡样本的呢?是调整权重还是过采样?请看源码:
if (info.labels[i] == 1.0f) w *= param_.scale_pos_weight
可见,应增加少量样本的权重。
此外,还可以通过上采样、下采样、SMOTE算法或自定义代价函数来解决正负样本不平衡的问题。
12.比较LR和GBDT,告诉我们什么情况下GBDT不如LR
我们先说一下LR和GBDT的区别:
在高维稀疏特征的场景下,LR一般表现优于GBDT。原因如下:
我们先看一个例子:
假设一个二分类问题,标签为0和1,特征有100个维度。如果有1w个样本,但是只有10个正样本1,并且这些样本的特征f1的值都是1,而剩下的9990个样本的f1特征都是0(这在高维中很常见稀疏的情况)。
我们都知道pg娱乐电子游戏,在这种情况下,树模型可以很容易地优化出一棵使用f1特征作为重要分裂节点的树,因为这个节点可以直接很好地划分训练数据pg网赌软件下载,但是当测试的时候,会发现效果很差,因为这个特征 f1 恰好与 y 符合这个模式。这也是我们常说的过拟合。
这种情况下,如果使用LR,也会出现类似过拟合的情况:y = W1*f1 + Wi*fi+….,其中W1特别大,无法拟合这10个样本。为什么此时树模型过拟合更加严重呢?
仔细想一想,你会发现现在的模型一般都有正则项,而LR等线性模型的正则项就是对权重的惩罚。也就是说,一旦W1太大,惩罚就会很大pg棋牌,进一步压缩W1的值,使He不至于太大。然而,树模型是不同的。树模型的惩罚项通常是叶子节点数和深度等,而我们都知道,对于上述情况,树只需要一个节点就可以完美划分9990个和10个样本。一个节点,产生的惩罚项极小。
这就是为什么在高维稀疏特征方面线性模型比非线性模型更好的原因:具有正则化的线性模型不太可能过度拟合稀疏特征。
13. XGBoost 中如何剪枝树 14. XGBoost 如何选择最佳分割点?
XGBoost在训练前根据特征值对特征进行预排序,并将其存储为块结构。以后节点分裂时可以重用该结构。
因此,可以采用特征并行的方法,利用多个线程计算每个特征的最优分割点,并根据每次分割后产生的增益,最终选择增益最大的特征的特征值作为最优分割点观点。
如果在计算每个特征的最佳分割点时遍历每个样本,计算复杂度会非常大。这种全局扫描的方式不适合大数据场景。 XGBoost还提供了直方图近似算法。对特征进行排序后,只选择常数个候选分割位置作为候选分割点,大大提高了节点分割时的计算效率。
15、XGBoost如何体现其可扩展性? 16. XGBoost如何评估特征的重要性?
我们使用三种方法来评估 XGBoost 模型中特征的重要性:
官方文档:
(1)weight - the number of times a feature is used to split the data across all trees.
(2)gain - the average gain of the feature when it is used in trees.
(3)cover - the average coverage of the feature when it is used in trees.注:这里的覆盖率是指某个特征作为分割点后,受其影响的样本数量,即有多少样本被该特征分割成两个子节点。
17. XGBooost 参数调整的一般步骤
首先需要初始化一些基本变量,例如:
(1) 确定学习率和估计器数量
您可以首先使用 0.1 作为学习率,然后使用 cv 来找到最佳估计量。
(2) max_深度和min_child_weight
我们调整这两个参数,因为这两个参数对输出结果影响很大。我们首先将这两个参数设置为较大的数字,然后继续迭代修改它们以缩小范围。
max_depth,每个子树的最大深度,从range(3,10,2)开始检查。
min_child_weight,子节点的权重阈值,从range(1,6,2)检查。
如果一个节点被分裂,并且其所有子节点的权重之和大于阈值,则叶子节点可以被分裂。
(3) 伽玛
也称为最小分割损失min_split_loss,取0.1到0.5之间的值,指的是分割一个叶子节点后损失函数减少的阈值。
(4) 子样本,colsample_bytree
subsample是训练的采样比例
colsample_bytree 是特征的采样比例
两者都检查从 0.6 到 0.9
(5) 正则化参数
alpha 是L1正则化系数,尝试1e-5, 1e-2, 0.1, 1, 100
lambda 是 L2 正则化系数
(6) 降低学习率
降低学习率,同时增加树的数量。通常最终的学习率设置为0.01~0.1
18. XGBoost模型过拟合如何解决?
当发生过拟合时,有两类参数可以缓解:
第一类参数:用于直接控制模型的复杂度。包括max_depth、min_child_weight、gamma等参数
第二类参数:用于增加随机性,从而使模型在训练时对噪声不敏感。包括子样本,colsample_bytree
另一种选择是直接降低学习率,但需要同时增加估计器参数。
19. 为什么XGBoost对缺失值的敏感度不如某些模型?
对于缺失值的特征,一般的解决方案是:
一些模型,例如SVM和KNN,在其模型原理中涉及样本距离的测量。如果缺失值处理不当,最终会导致模型预测结果不佳。
树模型对缺失值的敏感性较低,可以在大多数时候数据缺失的情况下使用。原因是,树中每个节点在分裂时,都是在寻找某个特征的最佳分裂点(特征值),完全没有必要考虑缺失特征值的样本。也就是说,如果某些样本 缺失的特征值缺失,对于寻找最佳分割点影响不大。
XGBoost 有处理丢失数据的特定方法。
因此,对于缺失处理后有缺失值的数据:
20.XGBoost和LightGBM的区别
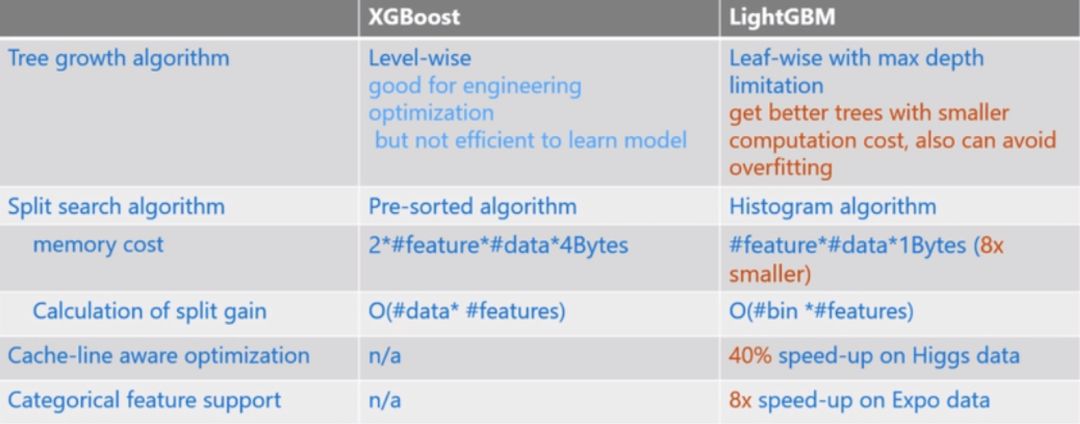
(1)树生长策略:XGB采用level-wise分裂策略,LGB采用leaf-wise分裂策略。 XGB对每一层的所有节点进行无差别的分裂,但有些节点的增益可能很小,这对结果影响不大,并带来不必要的开销。 Leaf-wise选择所有叶子节点中分割利润最大的节点,但容易出现过拟合问题,因此需要限制最大深度。
(2)分割点搜索算法:XGB采用特征预排序算法,LGB采用基于直方图的分割点算法。其优点如下:
但实际上,xgboost的近似直方图算法也和lightgbm的直方图算法类似。为什么xgboost的近似直方图算法还是比lightgbm慢很多?
xgboost 在每一层动态构建直方图。因为xgboost的直方图算法并不是针对特定的特征,而是所有的特征共享一个直方图(每个样本的权重是二阶导数),所以每一层都要重构直方图,lightgbm中每个特征都有一个直方图,所以构建一次直方图就足够了。
(3)对离散变量的支持:分类变量无法直接输入,因此需要提前对分类变量进行编码(如one-hot编码),而LightGBM可以直接处理分类变量。
(4)缓存命中率:XGB使用Block结构的一个缺点是,在获取梯度时,是通过索引来获取的,而获取这些梯度的顺序是按照特征大小的顺序,这会导致内存不连续使用权。可能会导致CPU缓存命中率较低,从而影响算法效率。 LGB基于直方图分裂特征,每个bin中存储梯度信息,因此访问梯度连续,缓存命中率高。
(5)LightGBM和XGboost的并行策略不同:
参考:
1.
2.
 鲁ICP备18019460号-4
鲁ICP备18019460号-4
我要评论